Introduction
The Linux kernel has a variety of synchronization mechanisms, each suited to a different context and set of constraints.
The simplest one of them all is the spinlock; spinlocks are used everywhere short, fast mutual exclusion is needed and blocking is either too costly or outright forbidden, such as in interrupt handlers and scheduler code.
Today, Linux spinlocks are implemented through a mechanism called qspinlock.
This article traces the evolution of spinlock designs that led to qspinlock, and presents a sample userspace C++ implementation along with benchmarks.
Spinlocks
Spinlocks are the simplest synchronization primitive to implement; as their name indicates, they spin on the lock until it is released.

Here is a sample implementation using the Test-and-Test-And-Set (TTAS) pattern, which is generally considered to be the most efficient:
struct SpinLock {
std::atomic<uint32_t> v{0};
void lock() {
for (;;) {
uint32_t expected = 0;
if (v.compare_exchange_weak(expected, 1, std::memory_order_acquire,
std::memory_order_relaxed))
return;
while (v.load(std::memory_order_relaxed) != 0)
cpu_relax();
}
}
void unlock() { v.store(0, std::memory_order_release); }
};It is important to note that spinlocks are inherently unfair: when the lock is released, all waiting CPUs race for it simultaneously, and there is no guarantee that the longest-waiting CPU will win. A CPU that is topologically closer to the releasing CPU, such as one sharing an L3 cache or sitting on the same NUMA node, will tend to win repeatedly, potentially starving remote CPUs indefinitely under sustained contention.
Ticket spinlocks
One way to implement fairness in spinlocks is using Ticket spinlocks, such locks work similarly to a deli counter: each waiter draws a ticket and is served strictly in order, providing a First-In-First-Out (FIFO) ordering.
These locks have the advantage that they provide a good bang for the buck: they are simple to implement, performant and provide guaranteed fairness.
Here is a sample implementation:
struct TicketLock {
std::atomic<uint32_t> next{0};
std::atomic<uint32_t> owner{0};
void lock() {
uint32_t my = next.fetch_add(1, std::memory_order_relaxed);
while (owner.load(std::memory_order_acquire) != my)
cpu_relax();
}
void unlock() { owner.fetch_add(1, std::memory_order_release); }
};Before moving to qspinlock, Linux used something similar for its locks, albeit fitting them in a single 32-bit value.
qspinlock
Motivations
If ticket spinlocks are so great, why did Linux switch away from them? The answer to this question lies in scalability: when a large number of cores contend on the same lock, this causes cache line bouncing, where the cache line of the lock is repeatedly transferred between CPUs, and each unlock invalidates every waiting CPU's cached copy simultaneously. With N waiters, a single unlock triggers N cache line transfers, increasing coherence traffic and causing latency to degrade as contention grows.
MCS Locks
Note: MCS Locks are better explained in this LWN Article and most of the information presented here comes from it.
One mechanism that solves this is the MCS lock (named after its authors), which eliminates cache line bouncing by giving each waiter its own cache line to spin on.
An MCS lock (or node) can be defined as such:
struct McsNode {
std::atomic<McsNode *> next;
std::atomic<int> locked; // 1 when acquired
};The way MCS locks work is via a sort of linked list, where each new waiter atomically appends its node to the tail of the main lock (called next), then spins on its own locked field until its predecessor wakes it up.
Let us walk through the process of acquiring and releasing an MCS lock.
First, CPU0 atomically swaps the tail pointer with a pointer to its own node and notices the previous value was NULL, indicating the queue was empty and the lock is now held by CPU0:

Now, CPU1 tries to acquire the lock, but it is contended: it notices the return value of the atomic exchange is non-NULL and sets the old tail's next value to its own McsNode, and spins on its own locked value until it is 1, ensuring spinning on CPU-local data:

When CPU0 releases the lock, it attempts to compare-and-swap (CAS) the tail pointer back to NULL. If the CAS succeeds, the queue is empty and the lock is free. If it fails, a successor has arrived, CPU0 then sets CPU1->locked = 1, waking CPU1 and handing off the lock.

Mechanism
At their core, qspinlocks are based on MCS locks, but they do not have MCS nodes directly embedded within them, as a means to save space and keep the lock to a single 32-bit word. That word is structured as such:

In this implementation, we will define a qspinlock as:
struct QSpinLock {
union {
std::atomic<uint32_t> val;
struct {
std::atomic<uint8_t> locked;
std::atomic<uint8_t> pending;
} low_word;
struct {
std::atomic<uint16_t> locked_pending;
std::atomic<uint16_t> tail;
} split;
};
};Here be dragons 🐉! Accessing multiple fields of a union is undefined behavior (UB) in C++. However, in practice all major compilers (GCC, Clang) treat this as well-defined. We accept the UB and move on.
Let's go through every field one by one:
locked: Set to 1 when the lock is held, and cleared on release. Waiters at the head of the queue spin on this byte waiting for it to reach 0 before taking the lock.pending: Used as an optimization when there is only one CPU waiting for the lock to be freed. Rather than setting up a full MCS queue node, the first waiter simply sets this bit and spins on locked.tail: Split into two subfields: the lowest two bits encode theqnodeslot index and the remaining bits encode the CPU ID of the tail node.
qnodes
The value encoded in the tail field indexes into a per-CPU array of MCS nodes called qnodes. Linux allocates 4 nodes per CPU.
The reason there is an array rather than a single node is to handle nested acquisition: if an interrupt fires on a CPU that is already waiting on the lock, it needs a separate node, so each CPU maintains a small array of nodes instead of just one (though it is discouraged to take locks in interrupts anyway!).
Let's now go through the implementation of locking.
Locking
Note: This implementation is mostly based on the actual Linux code, adapted for C++ and omitting extraneous checks
Constants
Let us first define a few useful constants related to extracting fields from the 32-bit word:
static constexpr uint32_t LOCKED_MASK = 0x000000FF;
static constexpr uint32_t LOCKED_VAL = 0x00000001;
static constexpr uint32_t PENDING_MASK = 0x0000FF00;
static constexpr uint32_t PENDING_VAL = 0x00000100;
static constexpr uint32_t TAIL_IDX_MASK = 0x00030000;
static constexpr uint32_t TAIL_CPU_MASK = 0xFFFC0000;
static constexpr uint32_t TAIL_MASK = TAIL_IDX_MASK | TAIL_CPU_MASK;
static constexpr uint32_t TAIL_IDX_OFFSET = 16;
static constexpr uint32_t TAIL_CPU_OFFSET = 18;Each _MASK constant isolates its field via a bitwise AND, for example, val & LOCKED_MASK extracts the locked byte. Each _VAL constant is the value written to set that field, LOCKED_VAL is 1 in bit 0, PENDING_VAL is 1 in bit 8. The _OFFSET constants are the shift amounts used when encoding and decoding the tail field: the slot index sits at bit 16, and the CPU ID at bit 18.
The fastest path
The fastest path happens when we try to grab an uncontended lock. In that case, we can just set the locked bit and be done:
void lock() {
uint32_t v = 0;
// Fastest path
if (val.compare_exchange_strong(v, LOCKED_VAL, std::memory_order_acquire,
std::memory_order_relaxed)) {
return;
}
// ...
}The medium path
The medium path happens when we try to grab a contended lock with no waiter.
First, we check whether the only bit set is pending, this indicates that a pending waiter is mid-transition, in the process of atomically clearing pending and setting locked to take ownership. We spin for up to PENDING_LOOPS iterations to let that transition complete:
if (v == PENDING_VAL) {
uint32_t cnt = PENDING_LOOPS; // 512 on Linux
while (cnt--) {
v = val.load(std::memory_order_relaxed);
if (v != PENDING_VAL)
break;
cpu_relax();
}
}Then, we check whether any bit but locked is set (i.e. either tail or pending is non-zero), which would indicate another waiter, in that case we go to the slow path:
if (v & ~LOCKED_MASK) {
queue(); // Go to slow path
return;
}As far as we know, there is no one contending on the lock, so we can set the pending bit:
v = val.fetch_or(PENDING_VAL, std::memory_order_acquire);However, fetch_or is not a CAS, another CPU may have raced us and modified the lock word between our initial check and this store. So we validate the value returned by fetch_or and check for contention once more:
if (v & ~LOCKED_MASK) [[unlikely]] {
if ((v & PENDING_MASK) == 0) {
// We set the pending bit but we shouldn't have, undo it.
val.fetch_and(~PENDING_VAL, std::memory_order_release);
}
queue(); // Go to slow path
return;
}Now, if the lock is still held, we spin on locked until it is cleared by the current holder:
if (v & LOCKED_MASK) {
while (low_word.locked.load(std::memory_order_acquire) != 0) {
cpu_relax();
}
}Once locked is clear, we atomically clear pending and set locked in a single 16-bit store:
split.locked_pending.store(1, std::memory_order_release);The slow path
The slow path occurs when we have no choice but to queue on the lock.
We first attempt to allocate an McsNode from our per-CPU stash by claiming a slot index from curr_idx,
if there is none available we have no choice but to spin on locked:
void queue() {
uint32_t idx = my_cpu->curr_idx++;
struct IdxGuard {
int &v;
~IdxGuard() { v--; }
} guard{my_cpu->curr_idx};
if (idx >= MAX_IDX) {
while (!try_lock())
cpu_relax();
return;
}
// ...
}The IdxGuard RAII pattern ensures the slot is released when queue() returns, regardless of which path we exit through. If all slots are exhausted, which should very rarely happen in practice, we fall back to spinning directly on try_lock() (which simply tries to CAS val with LOCKED_VAL).
We then initialize the node and make one last opportunistic attempt to grab the lock. As the Linux source notes, we have just touched a (possibly cold) cache line to initialize the node and someone may have released the lock while we weren't watching, so it is worth trying once more before committing to the queue:
McsNode *node = &cpus[my_cpu->id]->qnodes[idx];
node->locked.store(0, std::memory_order_relaxed);
node->next.store(nullptr, std::memory_order_relaxed);
// Try one last time
if (try_lock()) {
return;
}Now we have absolutely no choice but to queue, first encode the tail index:
uint32_t tail = encode_tail(my_cpu->id, idx);Where encode_tail is:
uint32_t encode_tail(uint32_t cpu_id, uint32_t idx) {
return ((cpu_id + 1) << TAIL_CPU_OFFSET) | (idx << TAIL_IDX_OFFSET);
}Note the cpu_id + 1: CPU IDs start at 0, so an ID of 0 would be indistinguishable from an empty tail field. Adding 1 ensures that a non-zero tail always indicates a real waiter.
We then atomically exchange the tail field with our new value, retrieving the previous tail:
uint32_t old = xchg_tail(tail);Where xchg_tail operates only on the upper 16 bits of the lock word, leaving locked and pending untouched:
uint32_t xchg_tail(uint32_t tail) {
uint16_t tail16 = tail >> 16;
uint16_t old_tail16 =
split.tail.exchange(tail16, std::memory_order_acq_rel);
return static_cast<uint32_t>(old_tail16) << 16;
}Now, we need to check whether or not we have a predecessor, and if so, we have to let it know of our presence by setting its next field to point to our node.
We then enter phase 1 of the two-phase wait, spinning on our own node->locked until our predecessor wakes us:
// Someone else was already waiting, set their next
if (old & TAIL_MASK) {
McsNode *prev = decode_tail(old);
prev->next.store(node, std::memory_order_release);
while (node->locked.load(std::memory_order_acquire) == 0) {
cpu_relax();
}
}The release store to prev->next and the acquire load of node->locked ensures the predecessor will not write to node->locked until it has observed our node via its own next pointer.
decode_tail simply undoes the encoding to recover the CPU ID and slot index:
McsNode *decode_tail(uint32_t tail) {
uint32_t cpu_id = (tail >> TAIL_CPU_OFFSET) - 1;
uint32_t idx = (tail & TAIL_IDX_MASK) >> TAIL_IDX_OFFSET;
return &cpus[cpu_id]->qnodes[idx];
}Once our predecessor has woken us, we are now the head of the queue. We enter phase 2: spinning on the main lock word until both locked and pending are clear, meaning the current holder has released the lock and no pending waiter is mid-transition:
uint32_t v = 0;
while (((v = val.load(std::memory_order_acquire)) &
(LOCKED_MASK | PENDING_MASK)) != 0) {
cpu_relax();
}Now we attempt to take ownership. If we are the only waiter in the queue, meaning the tail still points to our node, we try to atomically claim the lock and clear the tail in one CAS, leaving the lock word clean:
if ((v & TAIL_MASK) == tail) {
uint32_t expected = v;
if (val.compare_exchange_strong(expected, LOCKED_VAL,
std::memory_order_acquire,
std::memory_order_relaxed)) {
// No contention, we're done
return;
}
}If the CAS fails, a new waiter has joined the queue behind us since we last checked. In that case we cannot clear the tail, so we take a different approach: we set locked directly to signal ownership, then promote our successor to queue head by setting their node->locked to 1:
low_word.locked.store(1, std::memory_order_release);
McsNode *next = nullptr;
while ((next = node->next.load(std::memory_order_acquire)) == nullptr) {
cpu_relax();
}
next->locked.store(1, std::memory_order_release);The loop on node->next handles the inherent race in the two-step enqueue: a successor may have already swapped the tail but not yet written their next pointer. We simply wait for them to finish. Once next is visible, a single store to next->locked wakes the successor and hands off the queue head, completing the acquisition.
Summary
To summarize, the lock() function has three paths of increasing complexity:
- Fast path: the lock is uncontended, a single CAS is sufficient.
- Medium path: the lock is held but the queue is empty, we set the pending bit and spin on locked without touching the MCS queue.
- Slow path: the queue is occupied, we enqueue an MCS node, wait for our predecessor to promote us to head, then spin on the main lock word before taking ownership.
Unlocking
Phew, that was a lot to uncover for locking! Thankfully unlock() is very simple:
void unlock() {
low_word.locked.store(0, std::memory_order_release);
}This is actually the reason why we use a whole byte for locked instead of a bit: unlock() is as simple as an atomic byte store!
Benchmarks
It's fun to nerd out on implementation details but how much faster is qspinlock?
I have set up a simple benchmark, measuring SpinLock against TicketLock and QSpinLock, it consists of creating N threads (up to nproc) all pinned to their own CPU cores taking the lock and pushing 500 000 elements to a std::vector<int>:
for (int j = 0; j < OPS_PER_THREAD; j++) {
lock.lock();
shared_vector.push_back(j);
lock.unlock();
}We then wait for each thread to complete and measure the time taken:
auto t0 = std::chrono::steady_clock::now();
start.store(true, std::memory_order_release);
for (auto &t : threads)
t.join();
auto t1 = std::chrono::steady_clock::now();Here are the results:
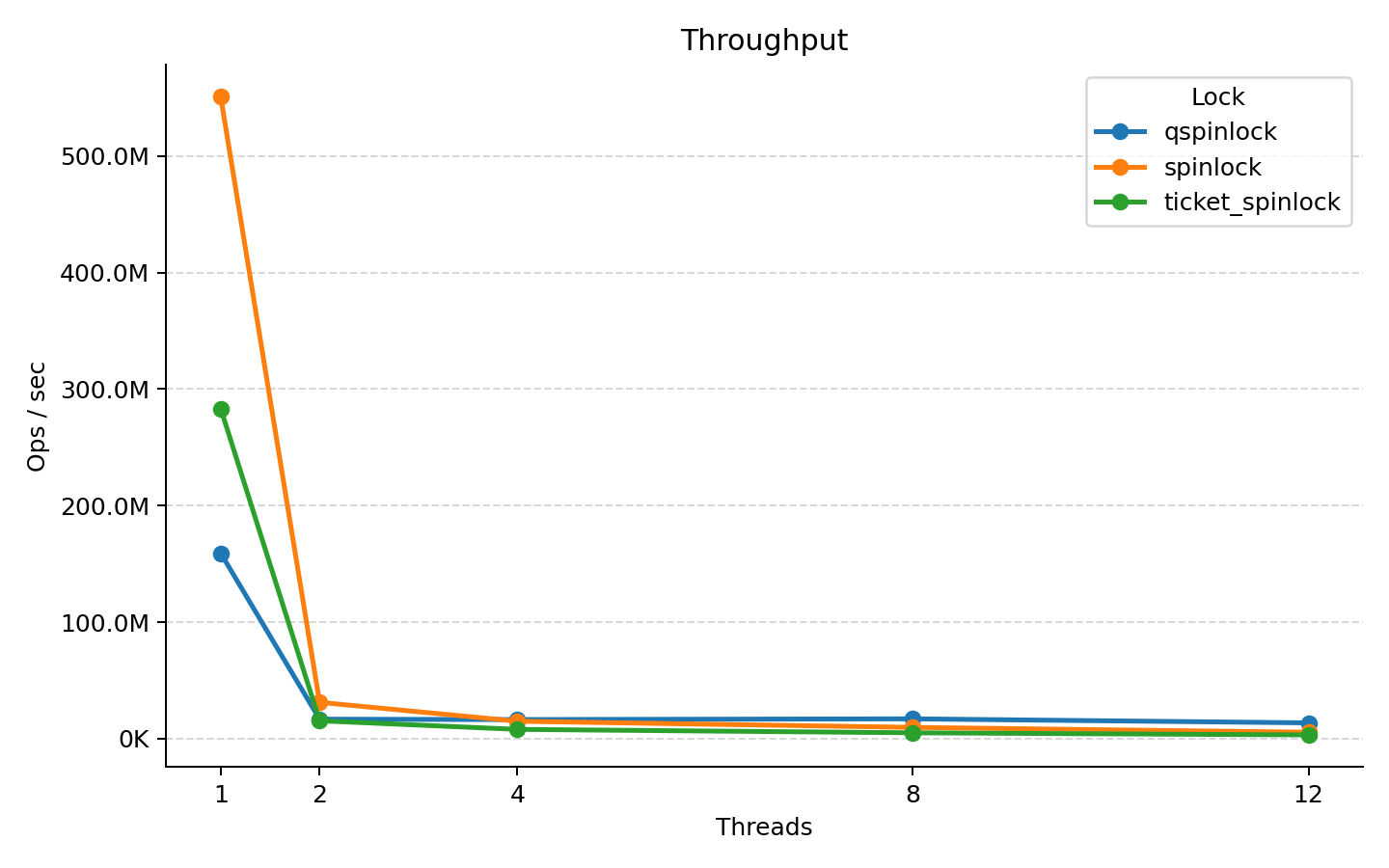
| Threads | Spinlock (ops/s) | Ticket Spinlock (ops/s) | qspinlock (ops/s) |
|---|---|---|---|
| 1 | 551,081,387 | 283,366,874 | 159,177,979 |
| 2 | 31,101,649 | 15,260,200 | 16,609,980 |
| 4 | 14,855,526 | 7,864,148 | 16,271,328 |
| 8 | 9,575,916 | 4,925,312 | 16,911,329 |
| 12 | 5,384,959 | 3,107,082 | 13,454,086 |
We can see the naive spinlock is much faster uncontended, which is expected since it is the simplest (albeit unfair).
We can also see qspinlock seems to scale better than both the naive spinlock and the ticket spinlock, maintaining relatively stable throughput as thread count increases.
Why is it so slow uncontended though?
In theory, qspinlock should be as fast as a spinlock in the uncontended case, so why is it not? Honestly, I'm not sure, but my best guess is that it is because of the very short critical section causing a store-to-load forwarding stall:
since we write to locked as a byte in unlock(), but access the value as a 32-bit integer in lock(), the CPU pipeline stalls and we end up with poor performance.
In fact, changing unlock() to:
void unlock() {
val.fetch_and(~LOCKED_VAL, std::memory_order_release);
}Yields the same unconteded performance as the ticket lock, which is expected since both need a Read-Modify-Write (RMW) operation. This is slower overall, though. Changing this to a simple store over the whole value (which is actually incorrect), yields the same uncontended performance as spinlock.
In practice, real critical sections are rarely that short, the additional work done while holding the lock gives the pipeline enough time to resolve the stall, so this might not be an actual concern. (Also, it only happens uncontended!)
Summary
qspinlock is not a silver bullet and its implementation is significantly more complex than either a plain spinlock or a ticket lock.
However, on a machine with many cores, as many as Linux needs to run on, the CPU-local spinning does make a measurable difference under sustained contention, even on my puny 6c/12t machine.
If you wish to dig deeper, I highly recommend:
- Reading the Linux code
- Reading this LWN Article
The code written for this article is available here
Thank you for making it this far!